Self-Benchmarking bei der Wartung einer chemischen Anlage
Claus Borgböhmer
Sasol Solvents Germany GmbH
Markus Ahorner
algorithmica technologies GmbH
Dr. Patrick Bangert
algorithmica technologies GmbH
Abstrakt
Wir schlagen hier vor, gängige Benchmarking-Studien durch eine Methode zu ergänzen bzw. zu ersetzen, die wir Self-Benchmarking nennen. Beim Self-Benchmarking wird der gegenwärtige Zustand einer Industrieanlage mit dem Zustand derselben Anlage in der Vergangenheit verglichen. Die beiden Zustände sind gut miteinander vergleichbar, sodass man Veränderungen sehr viel besser nachvollziehen kann. Dieser Ansatz basiert auf der Methode des Data-Mining, einer Methode, die zudem regelmäßig wiederholt und automatisiert werden kann. Sie ist darum schneller, kostengünstiger und aussagefähiger als reguläres Benchmarking. Am Beispiel der Wartung in der chemischen Industrie veranschaulichen wir, dass dieser Ansatz sehr nützliche und praktische Ergebnisse für die Chemieanlage hervorbringt.
Traditionelles Benchmarking
Es gibt eine ganze Reihe von Firmen, die Benchmarking-Studien für Betreiber von Industrieanlagen anbieten. Bei diesen Studien müssen die entsprechenden Einrichtungen einen Fragebogen ausfüllen, aufgrund dessen die Benchmarking-Firma einen Bericht erstellt, bei dem die zu bewertende Anlage mit anderen, ähnlichen Einrichtungen verglichen wird. Jede auf diese Weise bewertete Anlage kann anhand der im Bericht enthaltenen Statistiken ihre eigene Position erfassen und in verschiedenen Bewertungskategorien die Werte der „Klassenbesten“ ablesen. Die Anlage kann also leicht feststellen, wie sie im Vergleich zu anderen, ähnlichen Anlagen dasteht. Weil dieser Vergleich in mehreren Kategorien vorgenommen wird, kann man erkennen, in welchen Bereichen Verbesserungen sinnvoll sind. Auf diese Weise können solche Benchmarking-Studien zur Verbesserung der Anlagen führen.
Obwohl die Idee dieser hier beschriebenen Benchmarking-Studien zweifellos vernünftig ist, leiden derartige Studien an einigen systemimmanenten Schwächen:
- Erstens: Kein Teilnehmer kennt die Identität der anderen Teilnehmer, sodass die Definition von „ähnlichen Einrichtungen“ völlig in der Hand der Organisatoren der Studie liegt.
- Zweitens: Weil eigentlich keine zwei Einrichtungen wirklich miteinander vergleichbar sind, kann es sein, dass festgestellte Unterschiede in den jeweiligen Kategorien durch Dinge verursacht wurden, die völlig außerhalb des Einflussbereichs der für den Betrieb bzw. für die Wartung einer Anlage verantwortlichen Betreuer liegen – Unterschiede etwa, die auf die besondere Konstruktionsmerkmale während der Bauphase zurückgehen. Benchmarking-Studien können uns in Wirklichkeit nur Auskunft über die Art der Unterschiede geben, nicht jedoch über deren Ursachen (und damit auch nicht über deren Beseitigung).
- Drittens: Viele der (im Fragebogen gestellten) Fragen sind nicht präzise genug formuliert, wie sie – für einen wirklich aussagefähigen Vergleich – hätten formuliert werden müssen. Beispielsweise kann die Frage nach dem gegenwärtigen finanziellen Wert der Anlage auf sehr verschiedene Weisen beantwortet werden. Man kann zugrunde legen: (a) die bekannten Baukosten zum Zeitpunkt des Baus, (b) die derzeitigen Kosten für einen möglichen Wiederaufbau, (c) den gegenwärtigen Buchwert der Anlage, (d) den geschätzten Marktwert der Anlage usw. Es gibt noch weitere Möglichkeiten. Es ist klar, dass alle diese Angaben unterschiedliche Bedeutungen haben und für die Studie zu unterschiedlichen Schlussfolgerungen führen können.
Zusammenfassend muss gesagt werden, dass die Ergebnisse solcher Studien zwar tatsächlich zu positiven Veränderungen Anlass geben können, sie aber nicht unkritisch betrachtet werden dürfen. Häufig entbehren sie auch der wirklich aussagefähigen Informationen.
Self-Benchmarking
Als Alternative oder Ergänzung zu traditionellen Benchmarking-Studien schlagen wir hier eine Methode vor, die wir Self-Benchmarking nennen. Dabei wird der gegenwärtige Zustand der eigenen Anlage mit einem Zustand derselben Anlage zu einem vergangenen Zeitpunkt verglichen, um Entwicklungen und Unterschiede herauszuarbeiten. Wir werden hier zeigen, wie dies zu brauchbaren Ergebnissen führt.
Es wird sich zeigen, dass diese Methode alle oben genannten Schwächen des traditionellen Benchmarking umgeht:
- Zunächst: Wir wissen genau, wer an der Studie teilnimmt, da alle Beteiligten zu unserer eigenen Institution gehören.
- Zweitens: Wir wissen, wie vergleichbar die verschiedenen Teilbereiche unserer Einrichtung zueinander sind bzw. ob und wie die eigene Anlage heute im Vergleich zu früher dasteht.
- Drittens: Weil die Zahlen meist von einer einzigen Stelle kollektiv innerhalb der eigenen Einrichtung erfasst werden, gibt es keine Unsicherheit über deren Bedeutung und Vergleichbarkeit.
Es sei beiläufig erwähnt, dass eine solche Erhebung auch viel schneller und kostengünstiger durchgeführt werden kann, als wenn man an einer externen Benchmarking-Studie teilnimmt. Werden die Daten sachgemäß in einem Buchhaltungsprogramm der Einrichtung erfasst, kann dieses Self-Benchmarking sogar automatisiert und in monatlichen Intervallen leicht wiederholt werden, um auf diese Weise eine laufende (und stets aktuelle) Beschreibung der Verbesserungen und Defizite zu gewährleisten.
Wir wollen hier das Konzept des Self-Benchmarking an Hand der Wartungsabteilung von zwei Werksanlagen einer chemischen Herstellungsfirma in Deutschland veranschaulichen. (Die zwei Anlagen befinden sich in Moers und Herne.) Die Durchführung enthält folgende Phasen:
- Sammlung aller Wartungsmeldungen, Wartungsaufträge und Wartungsberichte. Dies erlaubt uns, die Wartungskosten in Personalkosten und Materialkosten bzw. in interne Kosten und externe Kosten aufzuteilen.
- Grobverarbeitung dieser Informationen, um Meldungen, Aufträge und Berichte jeweils vergleichbar zu machen. Dabei werden Daten gereinigt und für die weitere Analyse aufbereitet, indem nicht-vorhandene Einträge nachgetragen und Ausnahmesituationen entfernt werden; weitere Bereinigungs- und Standardisierungsschritte folgen [1].
- Zusammenführen der Informationen entsprechend der folgenden Dimensionen: nach Anlagen innerhalb einer Einrichtung (eine Anlage fertigt ein Produkt), nach Priorität der Wartungsmaßnahmen, nach Leistungstypen (d.h. Reparatur, Inspektion oder Konstruktion), nach Anforderungsart (Wartungsbedarf, Stillstand), nach Planungsgruppen, nach Abteilungen, nach Dauer der Wartungsarbeiten, nach Kostenkategorien (externe Materialkosten, interne Personalkosten). Innerhalb jeder dieser Dimensionen können wir die Zahl der Maßnahmen, die Gesamtkosten und die Durchschnittskosten tabellarisch erfassen.
- Duplizierung des soeben beschriebenen 3. Schrittes für vergleichbare Zeitabschnitte in der Vergangenheit, um auf diese Weise zeitliche Tendenzen der Einrichtung zu gewinnen, damit die Werksanlage mit sich selbst (zu einem früheren Zeitpunkt) verglichen werden kann.
- Interpretation der so gewonnen Daten und Erstellung eines entsprechenden Berichts. Die Interpretation fördert zwangsläufige Schlussfolgerungen zutage sowie Empfehlungen zur Verbesserung, beispielsweise zur Abwägung zwischen reaktiven und präventiven Maßnahmen. Sind die rohen Daten ausreichend gereinigt und die Kategorisierungen ausreichend detailliert, können zweckmäßige Verbesserungen direkt aus der Analyse herausgelesen werden.
In Schaubild 1 bieten wir ein Beispiel für diesen Prozess an. Die senkrechte Achse misst die relative Zahl der Wartungsaufträge für jede der wichtigsten drei Prioritätenebenen; also die Anzahl der Aufträge für jede Kategorie dividiert durch die Gesamtanzahl. Die waagerechte Achse beschreibt die verschiedenen Anlagen der Einrichtung. Die Reihenfolge der Anlagen in der waagerechten Achse wurde so bestimmt, dass die Anlage mit den meisten Aufträgen der Priorität 3 zuerst kommt. Die durchgezogene graue Linie stellt Priorität 3 dar, die gestrichelte Linie Priorität 2 und die gepunktete Linie Priorität 1. Wir sehen also, dass die Linie für Priorität 3 aufgrund der Sortierung der Anlagen stetig absinkt . Wir können leicht eine umgekehrte Beziehung zwischen den Prioritäten 1 und 2 erkennen. Wir sehen auch, dass Priorität 1 umso mehr zunimmt, je mehr Priorität 3 abnimmt. Wir können auch klar erkennen, dass einige Anlagen im Vergleich zu viele Priorität 1 Aufträge aufweisen. Durchschnittlich macht Priorität 3 nur 13% der Gesamtaufträge aus, aber es gibt Anlagen mit mehr als 50%. Je größer der Anteil von Priorität 1, umso weniger Planung wird durchgeführt und umso teurer werden die Wartungsaufträge. Anlagen mit mehr Aufträgen in Priorität 1 sollten ermutigt werden, ihre Aufträge mehr in Richtung Priorität 2 auszurichten, d.h. konkret: weniger Reparaturen bei Ausfällen und mehr geplante (präventive) Instandhaltung.
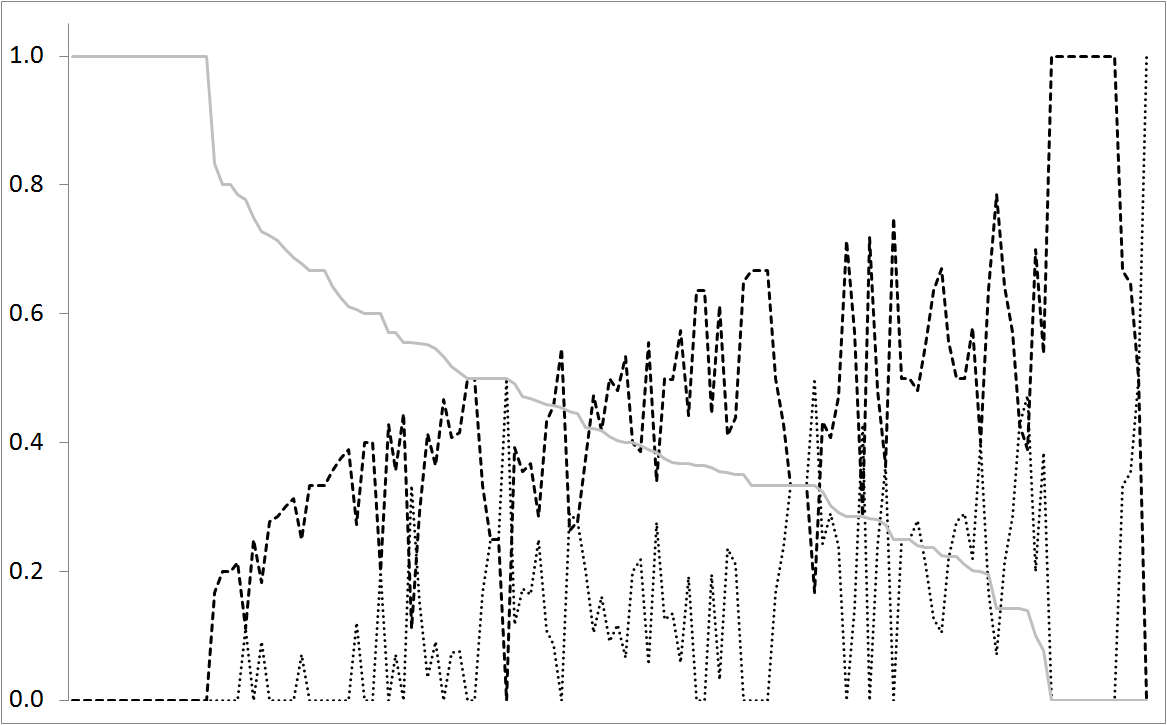
Schaubild 1.: Wir sehen hier die relative Anzahl der Wartungsaufträge für alle drei Prioritätsstufen relativ zur Gesamtanzahl der Aufträge. Priorität 1 wird durch die gepunktete Linie dargestellt, Priorität 2 durch die gestrichelte Linie und Priorität 3 durch die durchgezogene graue Linie. Die Anlagen wurden in abnehmender Reihenfolge nach Priorität 3 geordnet.
Ergebnisse und Schlussfolgerungen
- Im Laufe eines Jahres führt die Wartungsabteilung einer Werksanlage zahlreiche Maßnahmen durch, was einen großen Fundus an Daten ergibt, der es uns erlaubt, daraus repräsentative und sinnvolle Schlussfolgerungen zu ziehen. Dabei müssen wir zuvor statistische Ausreißer (Sonderfälle) sorgfältig von solchen Schlussfolgerungen ausklammern, da solche Sonderfälle die Statistiken geradezu ins Absurde verzerren können. Was ein Ausreißer ist, ist von Fall zu Fall zu entscheiden und kann auch nicht automatisiert werden. Eine ungewöhnlich teure Maßnahme könnte ein Kandidat für einen solchen Sonderfall sein, muss es aber dann nicht sein, wenn es sich dabei um eine regelmäßig wiederkehrende Maßnahme handelt.
- Nachdem die Daten auf diese Weise bereinigt wurden, können wir spezielle Durchschnittswerte mit den allgemeinen Durchschnittsgrößen vergleichen. So können wir etwa herausfinden, dass eine spezielle Art von Ausrüstung besonders günstig oder teuer in der Wartung ist. Ein Blick auf die Wartungsarbeiten wird zeigen, warum das so ist. Gewöhnlich gibt es spezielle Arten von Maßnahmen, die unverhältnismäßig hohe Kosten verursachen. Diese können wir als sogenannte Bad Actors identifizieren.
- Bad Actors sind also solche Anlagen, bei denen es oftmalige Betriebsausfälle gab oder die besonders teure Wartungsmaßnahmen erforderten. Tatsächlich handelt es sich meist um Maschinenteile mit unerwartet hohen Gesamtkosten. Hat man die Kosten von vornherein einkalkuliert, handelt es sich allerdings nicht um Bad Actors, sondern um „normale Akteure“. Die Kosten können sich zusammensetzen entweder aus vielen kleinen Ausfällen oder einigen wenigen großen Ausfällen. Insgesamt muss die Identifizierung von Anlagen, die als Bad Actors zu bezeichnen sind, durch eine sorgfältige Analyse bestimmt werden.
- Wenn wir die Maßnahmen nach ihren Prioritäten klassifizieren, stellen wir fest, dass Einordnung von Wartungsmaßnahmen als Erste Priorität (muss sofort durchgeführt werden) oder als Zweite Priorität (muss innerhalb von drei Arbeitstagen begonnen werden) ein wichtiges Element ist, um die Kosten von Wartungsmaßnahmen vorhersagen zu können. Ein und dieselbe Maßnahme wird nämlich, wenn sie als Priorität 1 durchgeführt wird, um 43% teurer sein, als wenn sie als Priorität 2 durchgeführt wird. Der Grund dafür ist, dass eine Maßnahme niederer Kategorie mehr Planung erlaubt, was die Arbeitszeit und manchmal auch die Materialkosten reduziert. (Es sei hier auch erwähnt, dass es möglich ist, einen Betriebsausfall schon Tage vor seinem tatsächlichen Eintreten vorauszusagen, sodass man viele Priorität-1-Fälle in Priorität-2-Fälle umwandeln und so die Kosten senken kann. Vgl. [2].)
- Aufgrund der Analyse von Wartungstypen (also Prioritätarten) kann man zwischen präventiven und reaktiven Wartungsarbeiten unterscheiden. Mehr präventive Wartung – so die Theorie – erfordert weniger reaktive Wartung. Allerdings gibt es einen optimalen Punkt der Prävention gegenüber der Reaktion, sowohl in Punkto Zuverlässigkeit als auch in Punkto Kostenfaktor. Dieses Optimum kann man herausfinden, indem man die Anlage mit sich selbst zu einem früheren Zeitpunkt vergleicht (nicht jedoch, wenn man diese Anlage in einer üblichen Benchmarkstudie mit anderen Anlagen vergleicht).
- Von besonderem Interesse für Instandhalter ist die Frage, ob die Wartungsarbeit von internem oder externem Personal durchgeführt wird oder ob das (Ersatz-)Material sich am Lager befindet oder eigens bestellt werden muss. Auch dies ist ein Punkt, der eher für das Self-Benchmarking spricht. Es hängt sehr davon ab, welchen allgemeinen Bedarf die Einrichtung hat beziehungsweise davon, was bei Dienstleistern extern, aber doch lokal verfügbar ist. Auch hierfür empfehlen wir das Self-Benchmarking, weil wir die Entwicklung über einen längeren Zeitraum nachvollziehen und so das Optimum herausfinden können. Gibt es genug Wartungsarbeiten dieser Art, ist es kostengünstiger, sie von internen Mitarbeitern durchführen zu lassen. Führt ein Ausfall zu relativ hohen Produktionsverlusten, ist es kostengünstiger, Ersatzteile auf Lager zu haben. Auch macht es Sinn, die großen Wartungsarbeiten von externen Dienstleistern durchführen zu lassen, wohingegen man die kleineren Arbeiten intern erledigen sollte. Auf diese Weise bleibt viel Know-how innerhalb des eigenen Betriebs. Im Allgemeinen wird es sehr hilfreich sein, eine klare Trennungslinie zu ziehen zwischen großen und kleinen Aufgaben, aber diese Kategorisierung kann nur innerhalb der jeweiligen Werksanlage erfolgen.
- Eine wichtige Entdeckung war, dass die Daten für Wartungsmeldungen, -aufträge und -berichte oft lückenhaft waren, weil Einträge entweder ganz fehlten oder einige Einträge nicht vollständig waren. Manche Arbeitsberichte waren fehlerhaft ausgefüllt. Solche Fehler und Lücken werden in vielen Unternehmen normalerweise nicht entdeckt, weil die Daten nicht auf inhärente Konsistenz hin überprüft werden. Beim Self-Benchmarking werden die Daten hingegen mit sich selbst verglichen, sodass Ungereimtheiten sofort sichtbar werden. Das hilft einem Unternehmen auch, seine Datenerfassung zu verbessern.
- Innerhalb der großen Datensätze kann es Anomalien geben. Statistisch gesehen sind Anomalien ungewöhnlich selten. So kann es beispielsweise sein, dass eine Wartungsaufgabe viel zu lange dauerte, zu aufwändig war oder zu viel Material erforderte usw. Die Suche nach solchen Ausreißern, die ein wichtiger Teil des Data-Mining darstellt, will ungewöhnliche Einträge erkennen (die dann gesondert behandelt werden) oder fehlerhafte Einträge identifizieren (die dann korrigiert werden müssen).
- Self-Benchmarking vergleicht den gegenwärtigen Zustand einer Anlage mit einem vergangenen Zustand derselben Anlage und zieht aus diesem Vergleich ähnliche Schlussfolgerungen wie bei einem normalen Benchmarking. Self-Benchmarking befasst sich vor allem mit Kosten und versucht, zukünftige Einsparungspotenziale zu erkennen. Wir haben dies am Beispiel der Wartungskosten von mehreren chemischen Anlagen untersucht.
Wir kommen zu mehreren Schlussfolgerungen: (1) Self-Benchmarking ist wesentlich schneller und günstiger als normales Benchmarking; (2) Self-Benchmarking zeitigt wertvolle Ergebnisse, die der Anlage hilft, Potenziale zu erkennen und Kosten zu sparen; (3) als Grundlage der Studie ist ein gutes Datenmanagement von entscheidender Bedeutung; dieses wird durch die erste Studie erheblich verbessert werden; (4) eine Reihe wertvoller Einsichten für den Arbeitsverlauf werden zutage gefördert, die einschlägige Verbesserungen ermöglichen; (5) diese Art der Studie kann automatisiert und regelmäßig wiederholt werden, sodass die Anlage in Punkto Wirtschaftlichkeit stets auf dem Laufenden bleibt.
Literaturhinweise
- Pyle, D. (1999): Data Preparation for Data Mining. Morgan Kaufmann.
- Bangert, P.D. (2012): Optimization for Industrial Problems. Springer Verlag.








